fediversesearchは、基本となるサーバー部とWebUIに関してはほぼ完成しました。クローラーに関しては初期に作成したコードがあり「クロールする」という点では動いていたのですが、運用する場合に「どこがボトルネックになっているのか調査しにくい」構造になっていました。
そこで、既存のコードからクロールに関するロジックはもらいながらもredis+sidekiqベースでの非同期処理に移行しました。非同期になることで、バッチ処理的なコードがすっきりしたものになるとともに、sidekiqのWeb画面で処理時間が明らかに異常な場合にどの分散SNSサーバーを見に行っているのかがわかるようになったので対策が打てるようになりました。
さて、分散SNSのサーバーのクロールですが、大きく2つの処理に分かれています。一つ目は、「peersリストをとってくる処理」です。mastodonなどかなりの種類のサーバーが「peers」という名前でWebAPIを提供しています。このAPIは、そのサーバーが接続したことのある別のサーバーをすべて列挙して返します。fediversesearch側としては、このサーバーのリストが検索対象となるサーバーにアクセスする元になります。fediversesearchのDBに登録されていないサーバーなら、新たに追加します。
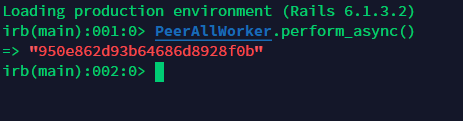
処理の呼び出し方はまだ考えている最中なので、現在はWorkerを直接実行しています。
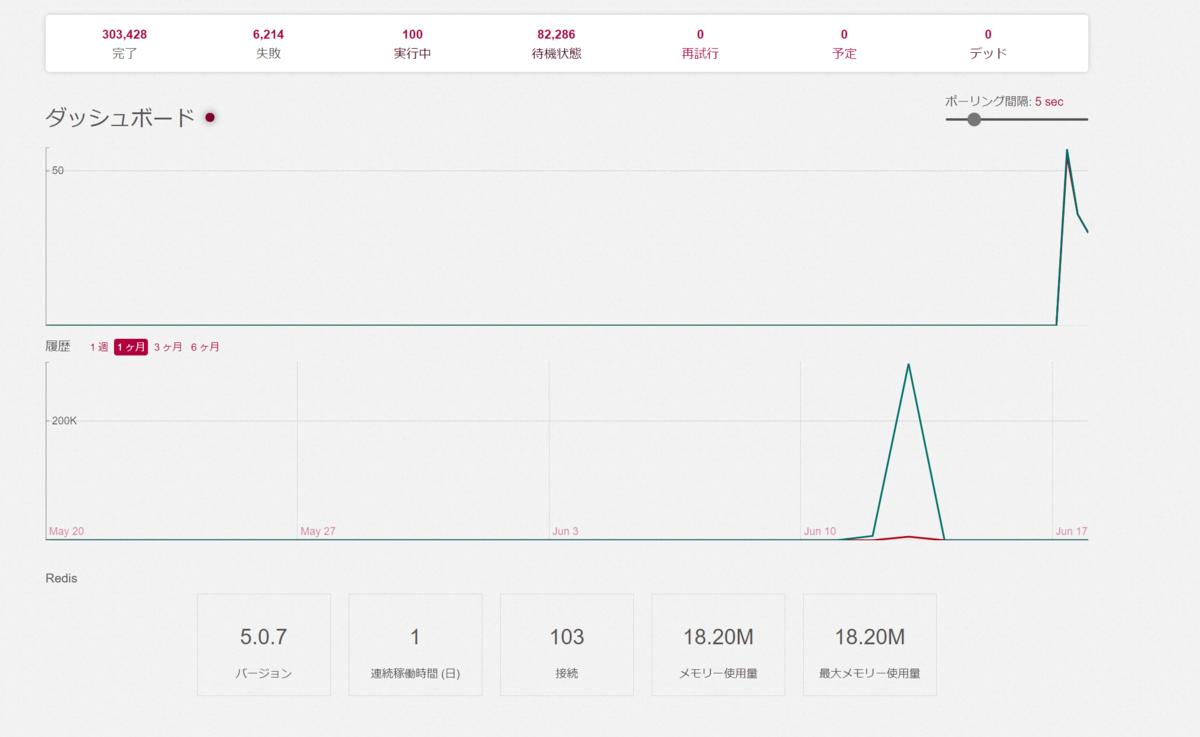
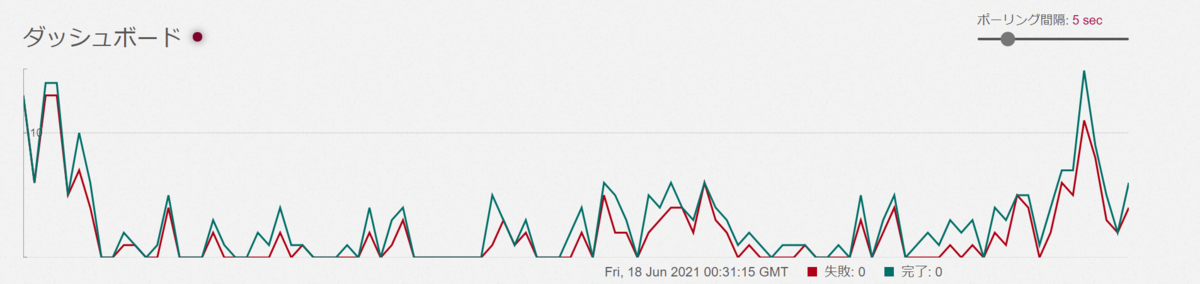
sidekiqで見るとこんな感じです。これは、DBに登録されている全サーバーに対してpeersリストを取得しに行っています。Peersがとれない場合(サーバーが存在しない、PeersAPIが存在しないなど)は失敗になっています。
二つ目は、「サーバー情報をとってくる処理」です。fediversesearchでは、狭義の「クロール」としています。いくつかのWebAPIを組み合わせて、「サーバーソフトウェアの種類」から「タイトル」「説明」などを取得します。現在は、masotodn互換APIとmisskey互換APIに対応しています。ここでは、まずそのFQDN(「サーバーのURLの一部を切り出したもの」と思ってください)からDNSサーバーに対して「IPアドレスが取ってこれるか」確認しています。実は、peersリストに載っている場合でもすでに停止したサーバーなどがあり、「IPアドレスが取れない」つまり「リクエストを送る先がないサーバー」に関しては「リクエストを送らないで終了する」実装にしています。
さて、IPアドレスがとれてひとまずサーバーが存在しそうな場合はWebAPIをいくつか呼び出します。呼び出したWebAPIごとに、ステータスが返ってきたらその内容ごとに異なる処理を実行しています。ソースコードを公開したほうが早いのですが、まだ定数などが切り出せていないのでコードの公開はお待ちください。

いくつかWorkerを用意しているのですが、これはCrawlNewsiteWorkerを呼び出しています。PeersリストからDBに新規追加されたサーバーを抽出してクロールを行っています。
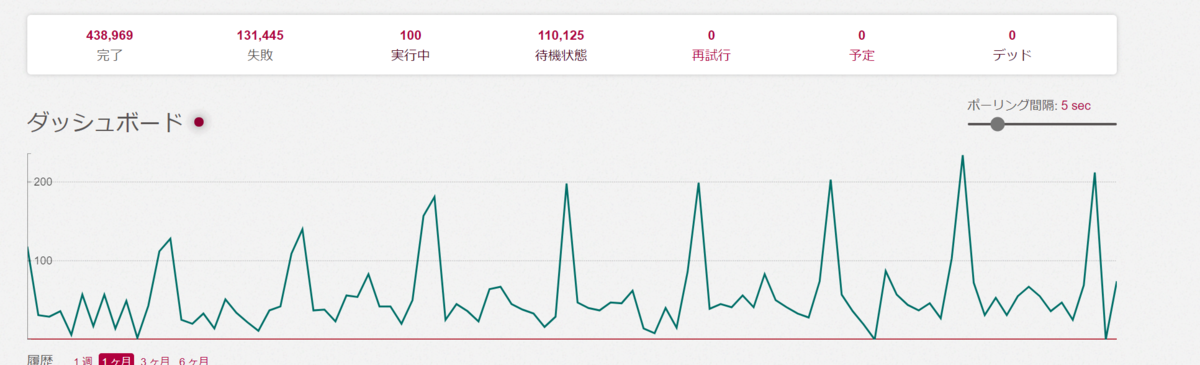
これもサーバー単位で非同期にクロールしています。まあ、1つのサーバーに対して多くても3つのWebAPIを順番にしか呼び出さないのでクロール対象のサーバーへの負荷は非常に低いです。呼び出すWebAPIも投稿一覧のような動的に変わるタイプではなく、サーバー自身の固定的な情報を返すやつなので。
このようにクロールができるようにはなっていますが、実際に動かしてみてわかったことがあります。それはまず、「Peersリストの返す値が異常にでかいサーバーがある」ということです。今fediversesearchを動かしているスペックのマシンで4時間経ってもPeerWorkerが終わらないサーバーが存在するので、sidekiqを一度強制停止してそのサーバーが返す値を調べたところ9万件以上のリストを返していたことがわかりました。実は、mastodon開発元が運営しているmastodon.socialや日本の代表的なサーバーであるmstdn.jpレベルの巨大なサーバーでも2万件以下なのです。返してくる値、すなわちサーバーのFQDNを確認したところ、「サブドメイン名がランダムな文字列になっている同じドメインが大量に登録されている」「ドメイン名ではなくメールアドレスとおぼしき@が入っている文字列が大量に登録されている」「FQDNではなく/に続いてユーザー名とおぼしき文字列が大量に登録されている」という3つの問題点が見つかりました。「@」と「/」を含む文字列については、その時点でFQDNではないと判断できるのでこの文字列はDBには登録しない&登録されていたら登録を削除するという処理を入れました。サブドメインがらみのものは自動判定するのは難しいので、ある程度決め打ちで「Peersリストが3万件を超えていたらそのPeersリストは使わない」という処理にしています。
なお、DBへのデータ登録・更新などの処理はfediversesearchのコアのサーバー部で一括管理しています。検索やオプトアウト以外のAPIに関しては、認証機構を組み込んでDBに登録しているユーザーに紐づけられたトークンを使わないとAPIを使用できないようになっています。ユーザーの登録処理などは、CUIのコマンドとして実装する予定です。
このような感じで、ひとまずfediversesearchで検索できるサーバー数は7000件に迫るレベルになりました。新しく立ち上がったサーバーなどもかなり追加されていますので、一度どんなサーバーがあるのか検索してみてください。