DBに格納されているURIに対してクロールを実行し終わり、有効なURIのうちサーバーのソフトウェア種別が取得できるものはある程度種類を絞り込んだうえでDBに保存しました。
ソフトウェア種別に関してはどう取得したらいいか悩んでいたのですが、分散SNSのフォロワーから「/.well-known/nodeinfo経由でとれないかな?」とのコメントがあり、試したところほぼこれで取得できるため実装しています。
あるサーバーの「/.well-known/nodeinfo」にアクセスすると、有効ならば以下のような形式のjsonデータが取得できます。

このうち、「href」に設定されているURIにアクセスすると、実際のデータがjson形式で取得できます。

今回は、softwareのnameの値を見ています。
この値は色々なものが返ってくると思われますが、今回は以下のサイトに掲載されている「Projects」の上位10個ぐらいを実際にfediversesearchで検索してみて実際に取得できるものに絞り込みました。
なお、「/.well-known/nodeinfo」のデータは1つとは限りませんので注意が必要です。

さて、実際に検索できるようにするためにUIとsearch APIを改造しました。
UIには「サーバー種別」をselectで選べるようにしています。
サーバー種別を指定して検索することが出来ます。
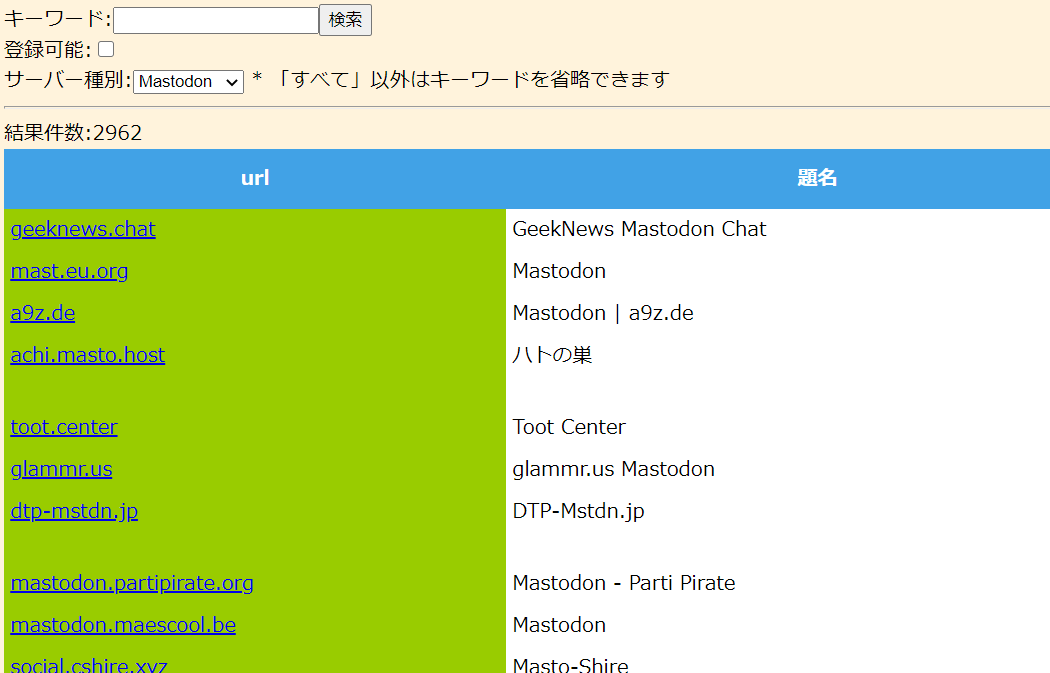
もちろん、キーワードとの組み合わせも可能です。
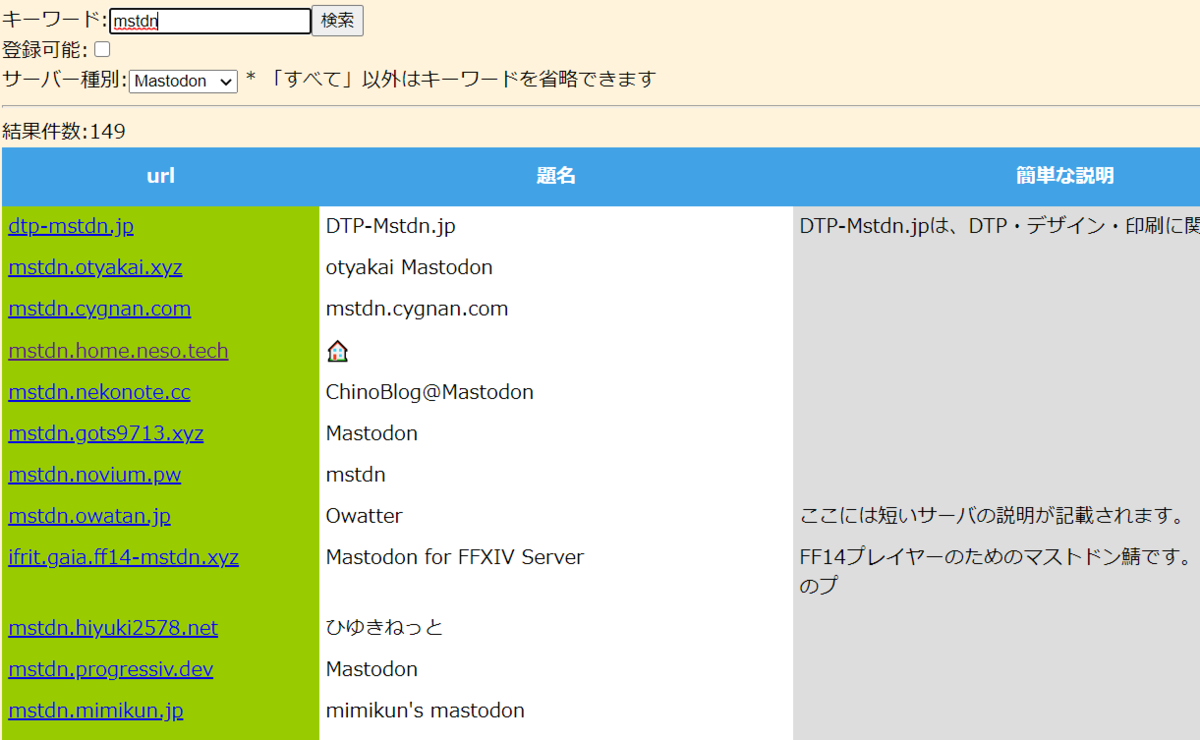
サーバー種別を指定しないケースは「-- すべて --」にしています。この場合、キーワードを指定しないと0件になります。
search APIですが、いままではキーワードを指定しない場合は0件で返していましたが、今回からキーワードが空文字列でもサーバー種別が指定されていたら検索できるようにしています。
パラメータは「software」で指定します。なお、keywordパラメータは省略できません。
モバイル画面も同じような改造をしています。
ひとまず、検索についてはひと段落です。次はオプトアウトの仕組みを実装していく予定です。